DBのメンテナンス性を重視したら、テーブル(表)を分けて管理した方が楽だよね?となる。売上テーブルに様々なユーザー情報を入れるより、ユーザーテーブル作ってユーザーを管理した方がユーザーの追加、修正、削除が楽になる。その上で、売上テーブルとユーザーテーブルを結合させる仕組み。
user_id を使いユーザーテーブルと売上テーブルを結合する。
売上テーブル(例)
*user_idを外部キーとして使う 。 order_id等、売上(販売個数・単価) 情報が格納されてる
ユーザーテーブル (例)
*user_idを主キーとして使う。ユーザー情報(ステータス・電話番号・住所等)が格納されてる
主キー特徴
・ nullが無い
・一意なデータ
join 基本構成(例)
select*
from uriage - 結合元の左テーブル as a
join user - 結合先の右テーブル as b
on uriage.user_id = user.user_id
または
using ( user_id )
join 3種
テーブル結合時に使用する、マーケターが覚える必要のあるJOINは3つに過ぎない。 join 、left join、right join 。
join
売上テーブルとユーザーテーブルの互いの条件に一致するレコード(データ行)のみを抽出。
*売上に貢献していないユーザーは無視。
left join
左テーブル全レコード取得。 右テーブルにある全user_idは不明だが、全 order_id知りたい。
*売上に貢献していないユーザーは無視。(右テーブルに)登録してないユーザーのデータはnullとなる。
right join
右テーブル全レコード取得。左テーブルにある全 order_id 不明だが、全user_id知りたい。
結合例
1
select
sp.user_id,
sp.product_id,
sp.unit_price,
sp.quantity,
us.user_status,
us.user_name
from data.sample as sp
left join data.user as us
using(user_id)
order by sp.user_id
using は on でも代用可。
on の場合、「sp.user_id = 'ABC'」のように絞り込み可。
1)
from data.sample as sp
left join data.user as us
on sp.user_id_id = us.user_id and sp.user_id = 'ABC'
2)
from data.sample as sp
join data.user as us
on sp.user_id_id = us.user_id and sp.user_id = 'ABC'
*1)left join ではABC以外のユーザーに関わるデータ unll 。
*2)join では両方のtableに入ってるもののみ表示。ABC以外のデータは非表示。
2
select
case cu.gender
when 1 then '男性'
when 2 then '女性'
else 'その他'
end as seibetu,
count(pu.purchase_id) as kounyuukaisuu,
sum(pu.quantity) as kosuu,
sum (sales_amount) as kounyuukinngaku,
from
data,purchases as pu
left join data.customers as cu
on pu.user_id = cu.user_id
group by cu.gender
order by seibetu
*case cu.gender は case cu.gender列を指定している。
その列の内容をcase で分けている
*seibetu以外は行カウントや列内の値を合計している。
seibetuでgroup by しなければならない。
データを探索
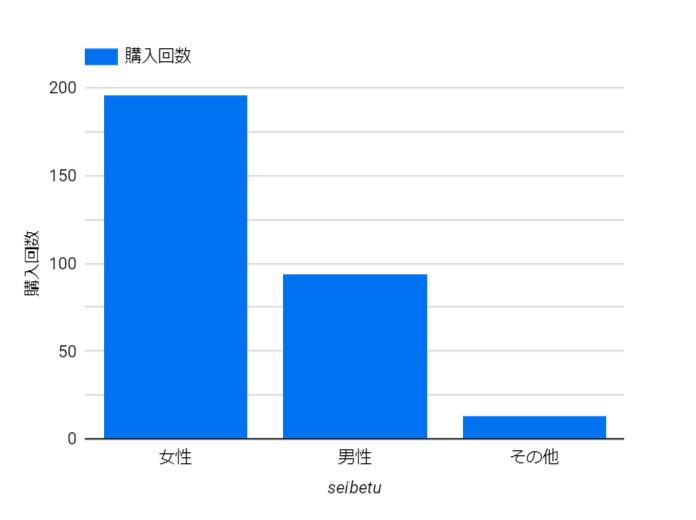
データを探索「lookerStudioで調べる」を使い、BigQuery付属のカスタムSQLで処理してグラフ化した。
kounyuukaisuu (購入回数)×性別。
3
select
datetime_diff('2023-12-31',cu.birthday,year) as nenrei,
case cu.status
when 1 then 'ゴールド'
when 2 then 'シルバー'
end as ranking,
round (avg (pu.quantity),0) avg_qty
from data.purchases as pu
left join data.customers as cu
using(user_id)
where status <> 3
group by nenrei,ranking
order by avg_qty desc
limit 3
*statusで 3(レギュラー)を除いている。
where status <> 3。using の下に配置。
group by nenrei,ranking
2つの列をグループ化。セカンダリディメンション?
round (avg (pu.quantity),0)
デフォは第二引数に「0」が入っている状態と同じ。
出力の小数点はコンマゼロ。
例: 3.0 や7.0。
*datetime_diff は date_diffでも可
date_diff(引かれる日付A,引く日付B,差分をしりたいデイトパート)
datetime_diffは細かい設定可(年,月,日,時,分,秒)
4
select
concat(cu.last_name,'',cu.first_name) as onamae,
sum(pu.sales_amount) as uriage
from
data.purchases as pu
left join data.customers as cu
using (user_id)
where cu.Is_premium is false and concat(cu.last_name,'',cu.first_name) is not null
group by cu.last_name,cu.first_name
order by 2 desc
limit 3
*concatでの文字列連結時にひとつでもnullがあると結果的に「null」扱いになる。
where cu.Is_premium is false and cu.last_name is not null and cu.first_name is not nullでも可。
*where cu.Is_premium is false。
Is_premiumがブール型であることの確認を事前にしておく。
5
select
case cu.gender
when 1 then '男性'
when 2 then '女性'
end as seibetu,
sh.tantou_name as kachou,
sum(pu.sales_amount) as goukei,
count(user_id) as kyakusuu
from
data.purchases as pu
left join data.customers as cu
using(user_id)
left join data.shops_master as sh
using(shop_id)
where gender <>3
group by seibetu,kachou
order by seibetu,goukei desc
* left join は正式名 left outer join。省略時の間違いに注意。
outer join ×
left join 〇
*group by・order byはpuとかcuとかshとかいらない。as の別名でよい
group by seibetu,kachou
6
select
sh.chief_name as kachou,
count(*) as kaisuu,
sum(pu.sales_amount) goukei
fromdata.shop_purchases as pu
left join data.customers as cu
using(user_id)
left join data.products_master as pr
using(product_id)
left join data.shops_master as sh
using(shop_id)
where date_trunc(pu.date,month) = '2020-04-01' and cu.prefecture <> 'Osaka' and pr.prod_status = 'g'
group by kachou
order by goukei desc
*where に pu/ cu/ pr sh つける。
*where にand 追加で様々な制限をつける。
*date_trunc(pu.date,month) = '2020-04-01'を使い 4月に丸める。4月1日~4月30日。
7
select
pr.prod_name as seihin,
max(pu.sales_amount) as max_am,
min(pu.sales_amount) as min_am,
max(pu.sales_amount) - min(pu.sales_amount) as sabun
from
data.shop_purchases as pu
left join data.customers as cu
using(user_id)
left join data.products_master as pr
using(product_id)
left join data.shops_master as sh
using(shop_id)
where sh.chief_name like '田中%' and cu.Is_premium = true
group by seihin
order by 4 desc
limit 3
*田中% は前方一致でマッチさせている。
*max(pu.sales_amount) - min(pu.sales_amount) で差分を取得。
*差分が大きい順に配置。order by 4 desc。
参考:BigQuery で学ぶ非エンジニアのための SQL データ分析入門

